


 皖ICP备19013955号
皖ICP备19013955号
微信扫码
添加专属顾问
我要投稿
AI生成的图片(如Stable Diffusion作品)自带“文字基因”——每张图都源于一段文本提示(Prompt)。但传统图像质量评估(IQA)仅关注画面本身的清晰度、色彩等,却忽略了 图文是否匹配 这一核心问题。比如,一张高清晰度的“太空猫”图片,若文字提示是“海边日落”,即便画面精美,质量评分也应大打折扣。
论文作者通过实验证明:传统IQA模型(如ResNet50)会因忽略文本信息而 高估质量分 。因此,如何让模型“既看画又读文”,成为提升评估准确性的关键。
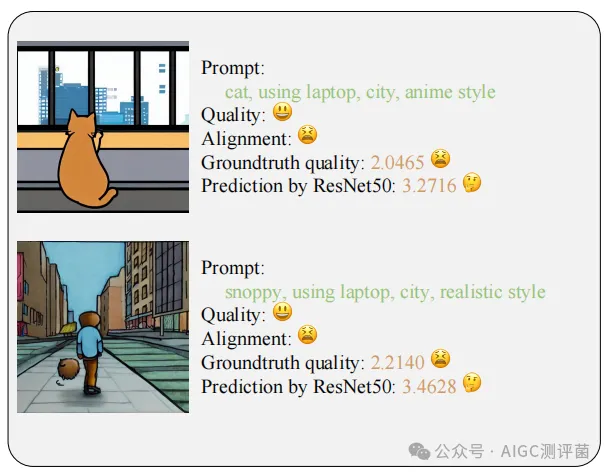
图1:文本-图片一致性评分 来源:论文
北大团队提出的 IP-IQA框架 ,首次将文本提示与图像结合,实现多模态质量评估。其核心设计如下:
问题 :现有模型(如CLIP)基于互联网图片训练,与AI生成图存在 领域差异 。
解法 :在2万张AI生成图(来自DiffusionDB)上增量训练,通过对比图像与文本的嵌入向量,缩小模态差异,提升模型对AGI的理解能力。
用 交叉注意力机制 对齐图像与文本特征。例如,模型能自动关联“城市夜景”文本与图中灯光区域(如图3)。
引入 特殊[QA]标记 :替换传统文本结束符,引导模型在编码文本时聚焦质量相关词汇(如“高清”“风格一致”)。
图像编码器与文本编码器双管齐下,最终输出综合评分。针对不同数据集(如AGIQA-3k),模型可分别预测 画面质量分 与 图文匹配分 ,满足多样需求。
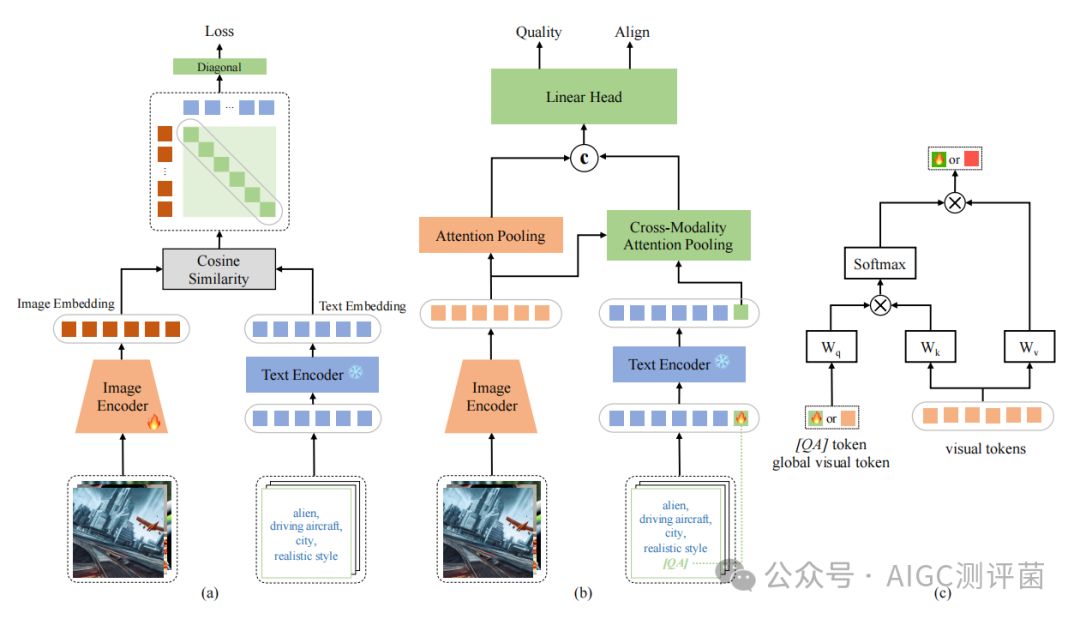
图2: IP-IQA框架图 来源:论文
数据集 :AGIQA-1k(1080张图)和AGIQA-3k(2982张图),评分涵盖画面质量与图文匹配。
指标 :SRCC(排名相关性)、PLCC(线性相关性)等。
结果 :
在画面质量评估上,IP-IQA的SRCC达到 0.8401(AGIQA-1k) 和 0.8634(AGIQA-3k) ,超越第二名2%以上。
在图文匹配评估上,IP-IQA同样领先,SRCC达 0.7578 ,优于CLIPScore等传统方法。
关键结论 :仅依赖单模态(如图像)的模型难以准确评估AGI质量,多模态融合是未来趋势!
' fill='%23FFFFFF'%3E%3Crect x='249' y='126' width='1' height='1'%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
应用场景 :优化AI绘图模型(如Midjourney)、自动化内容审核、提升生成式AI的用户体验。
局限性 :尚未深入挖掘图像与文本的复杂关系(如逻辑一致性),未来或引入知识图谱增强推理能力。
开源福利 :代码已公开,开发者可快速接入自己的AGI评估系统!
IP-IQA的诞生,不仅是技术突破,更揭示了多模态学习的巨大潜力——当机器能同时理解文字与图像,离真正的“创造力评估”或许不再遥远。未来,我们期待更多工作探索AI生成内容的深层质量维度,为人机协作打开新可能。
论文地址
:
https://ieeexplore.ieee.org/abstract/document/10688254
代码仓库
:
https://github.com/Coobiw/IP-IQA
👉
关注我,每日九点半,了解AI最新技术动态,一起学习一篇顶尖论文吧!
#AI #图像生成 #科技前沿 #论文速递 #人工智能 #质量评估
产品:场景落地咨询+大模型应用平台+行业解决方案
承诺:免费场景POC验证,效果验证后签署服务协议。零风险落地应用大模型,已交付160+中大型企业
回到顶部
